vLLM¶
vLLM is open-source LLM inference & serving engine.
It was launched in 2023, with goal to build the fastest and east-to-use open-source LLM inference & serving engine. vLLM builds on techniques like paged attention, continuous batching, distributed inference, automatic prefix caching, quantization and others to optimize GPU memory usage. It focuses on minimizing memory wastage and achieving higher throughput.
For getting started with vllm, we can install it with pip install vllm or use docker and do vllm serve Qwen/Qwen2.5-1.5B-Instruct or import in python script and do outputs = LLM(model="facebook/opt-125m").llm.generate(<prompts>, <sampling_params>). vLLM supports
Features¶
In 2023, vLLM announcement introduced Paged Attention:
Paged Attention:¶
Paged Attention is a memory optimization technique in which rather than allocating a large continuous block of memory for storing the KV cache (key and value tensors stored during model inference for attention computation), it breaks down the KV cache into smaller, non-contiguous memory blocks, and pages them, similar to how operating system manages virtual memory.
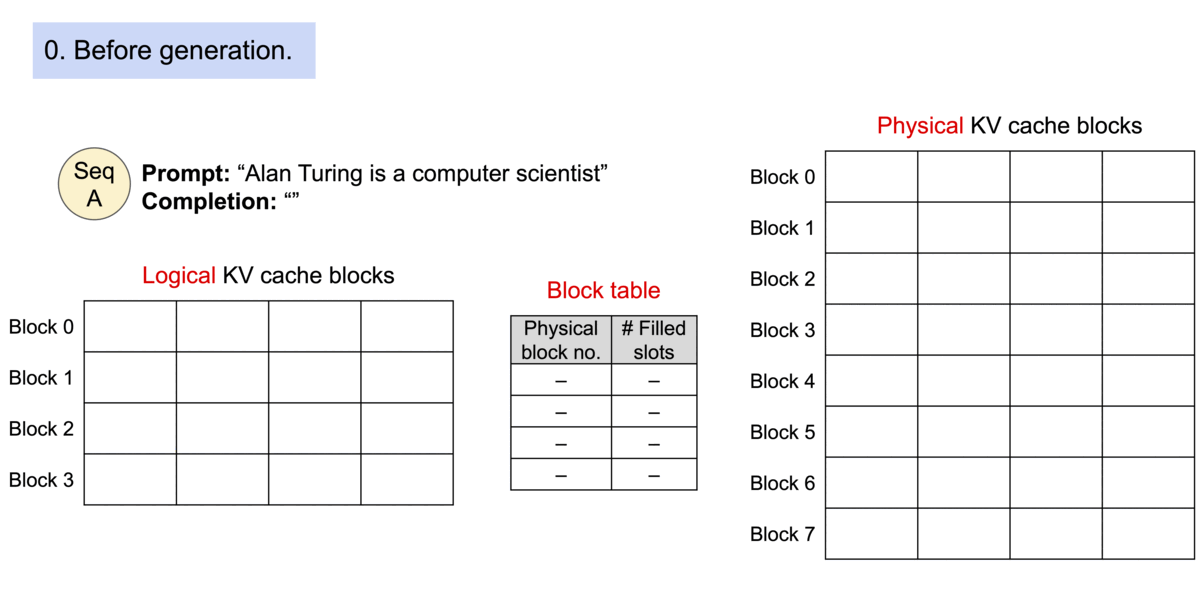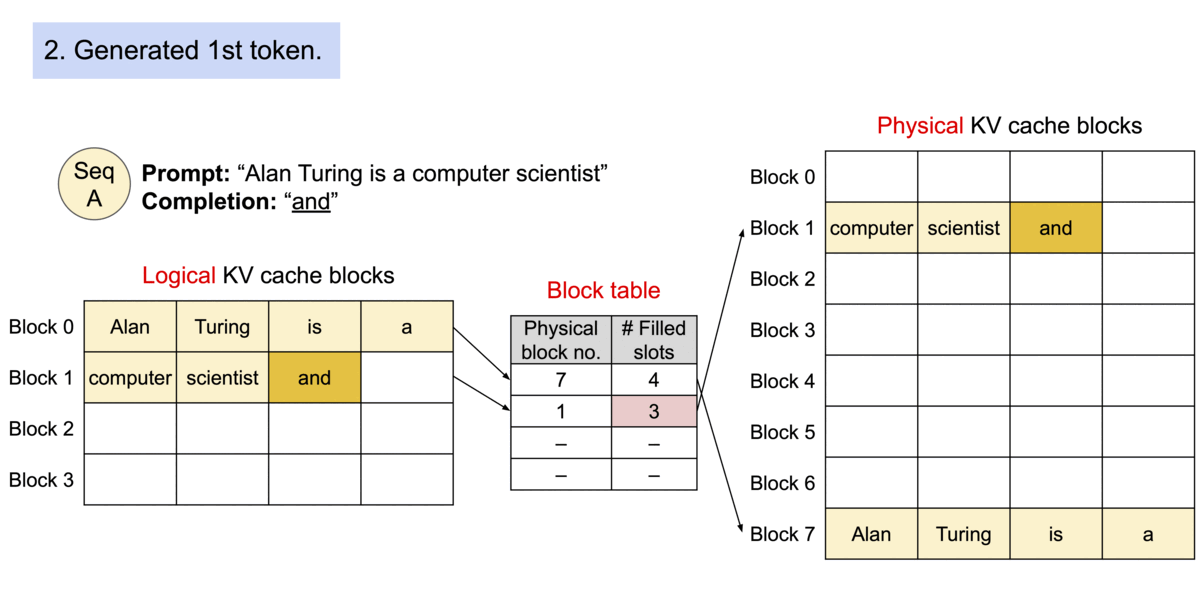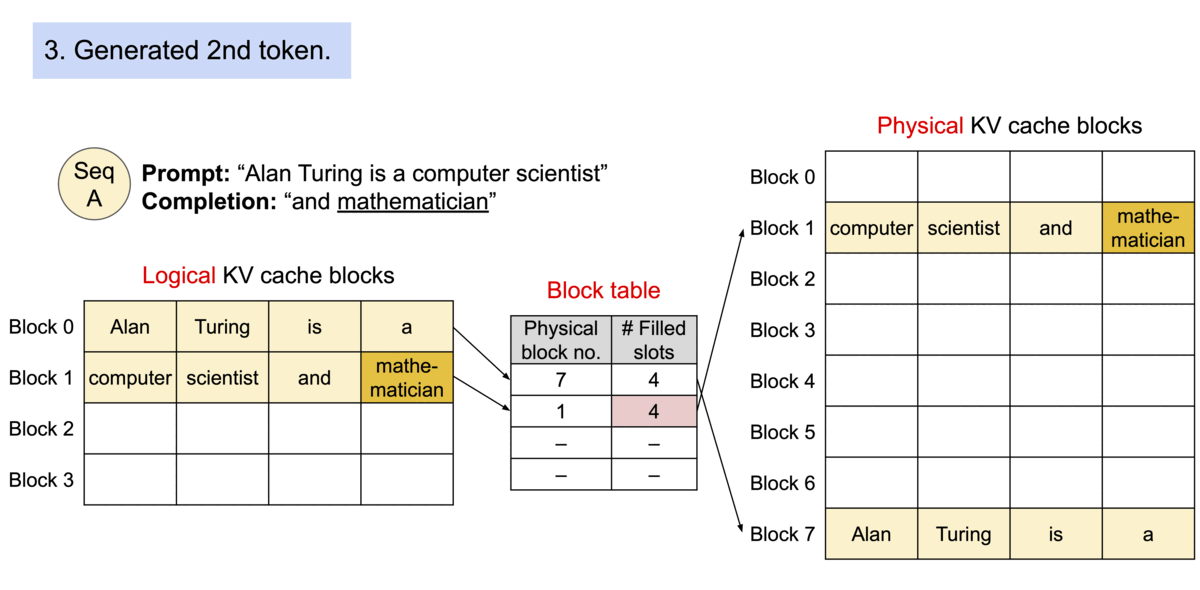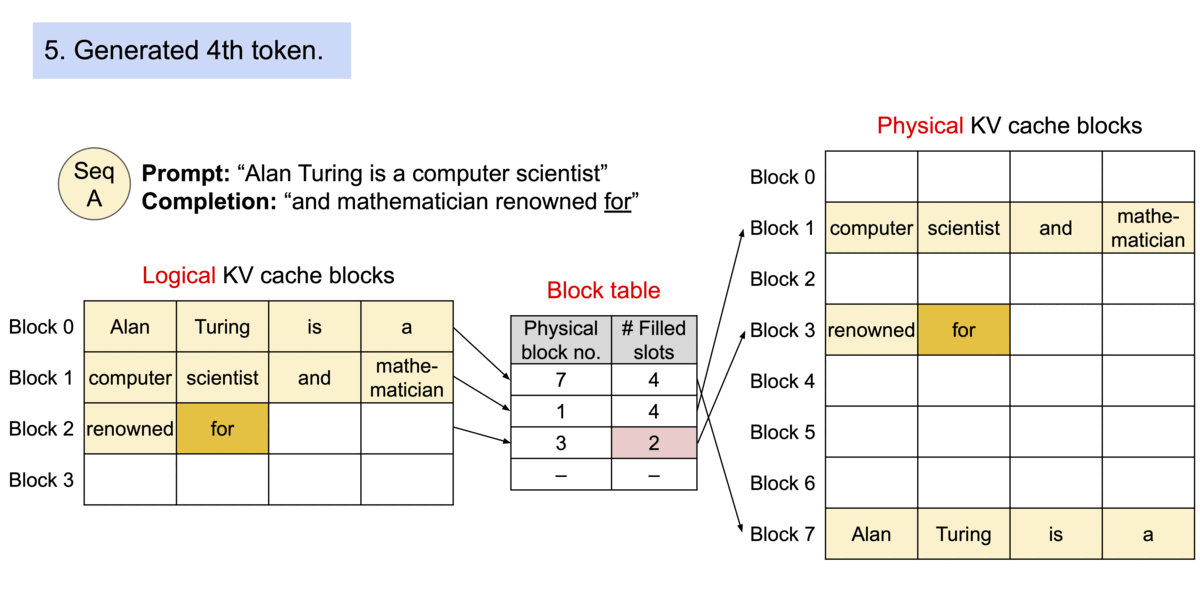
As a model generates new tokens, previously computed Key and Value tensors for all past tokens are stored in the KV cache. This cache is used to preserves context during generation by allowing the model to reuse these tensors and attend to earlier tokens without recalculating them each time.
The size of the KV cache depends on the sequence length and the model parameters. Longer sequences and larger models result in a larger KV cache, often reaching several gigabytes (GB). To understand this better, check out Calculating KV cache size for a LLM
KV caches typically require large blocks of memory. However, allocating such large, contiguous blocks can lead to fragmentation. As memory becomes fragmented, free space is split into smaller, non-contiguous chunks, making it difficult to allocate the large blocks that KV caches need. This leads to inefficient memory use and increased latency, as the system struggles to find enough contiguous space when required.
Paged Attention solves this by paging the KV cache — dividing it into smaller, dynamically allocated memory blocks that can be placed non-contiguously throughout available memory. This approach mirrors how operating systems manage virtual memory, enabling more flexible and efficient use of available resources.
With Paged Attention memory is dynamically allocated, so only the needed amount is used — avoiding overallocation, it reduces fragmentation by fitting smaller blocks into available gaps in memory, hence enhancing overall memory efficiency.
Architecture¶
Does vLLM support swapping to offload data to CPU memory? Fash Attention
References: - vLLM announcement introduces paged attention - Paged Attention paper